Spotify è incredibilmente comodo: tra i vari servizi di streaming musicali provati è probabilmente quello che più si avvicina a ciò di cui ho bisogno (e lo dice una persona che al tempo pagava Google Music per riempirsi le orecchie di canzoni). Nel tempo però sono diventato sempre più allergico a diversi aspetti legati a questo servizio:
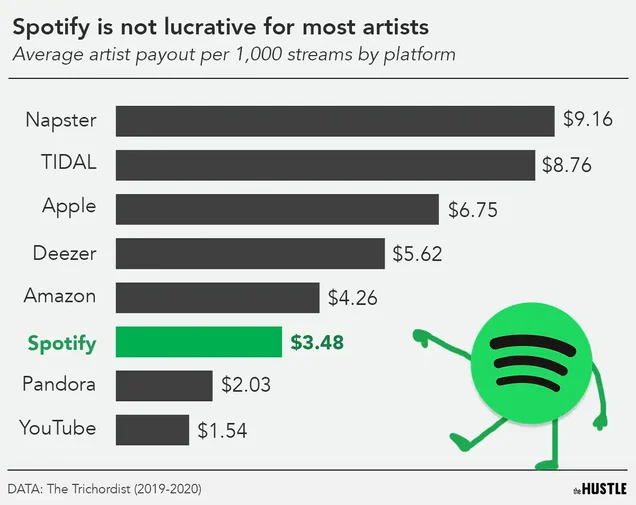
L3 musicist3 vengono pagat3 uno sputo (e praticamente senza diritti, specialmente se non sei famos3)
Nonostante gli aumenti di prezzo (l'ultimo annunciato pochi giorni fa) e le azioni che continuano a crescere i Layoff (licenziamenti) la fanno ancora da padrone
L'alternativa che fa al caso mio? Navidrome.
Un software Open Source con supporto alle Subsonic API (permettendo l'utilizzo da diversi client, tra le altre cose).
Vediamo come tirarlo in piedi in cinque minuti e come iniziare a caricare la nostra musica lì sopra.
Sì, anche quella che abbiamo su Spotify.
Sì, anche le Playlist invece delle canzoni singole.
Chi mi conosce sa che ho un rapporto complicato con l'intelligenza artificiale.
Ritengo sia qualcosa di eccezionale, ma usato non nel migliore dei modi.
Diciamo che si può riassumere tutto al meglio con questo meme così non mi perdo in sproloqui:
Ora che abbiamo smarcato questo doveroso preambolo arrivo al punto: avevo bisogno di trascrivere degli audio in locale (sai com'è, la privacy e tutto il resto...) e mi son messo a guardare software e strumenti per farlo senza dovermi ascoltare ore di registrazioni. Ho così scoperto l'esistenza di un software Open Source chiamato Whishper che sfrutta l'AI per fare esattamente ciò di cui avevo bisogno.
Da qualche tempo ho smesso – in modo più o meno drastico – di utilizzare i principali social network.
Anche tralasciando la mia “deriva fediversistica” sono arrivato al punto in cui i contenuti che fruivo quotidianamente non erano di fatto qualcosa di scelto da me.
Il feed di Twitter, i Reel di Instagram, gli Short di Youtube, i video di TikTok... tutte cose che puntano a massimizzare il tuo tempo su una determinata piattaforma dandoti in pasto una vasta quantità di contenuti che ti creano dipendenza [1] e ti spingono al Doomscrolling.
Già, ma come ne esci se tra tutti quei contenuti ce ne sono effettivamente di interessanti che vuoi continuare a seguire?
Anche stanotte – come spesso è capitato negli ultimi mesi – sono finito a fare le ore piccole per lavorare a progetti che puntano a farci “riprendere qualche piccolo spazio di web”.
Se quest'ultimo concetto mi sembra incredibilmente ambizioso (e a volte mi stupisco di come Livello Segreto sia riuscito a ritagliarsi il suo spazio e continui a crescere a un anno e mezzo dalla sua creazione), la mia attenzione in questi giorni va a quel “farci” e al plurale che mi sta regalando più soddisfazioni di quante potessi immaginare.
Lavorare a software che di fatto stanno ancora nascendo e collaborare gomito a gomito con persone curiose come me (o, ancora meglio, direttamente con le sviluppatrici e gli sviluppatori) mi riporta a quei bei tempi™ delle serate ai Linux User Group, dei forum brulicanti di utenti attivi e a quella meravigliosa sensazione che solo il collaborare a qualcosa di comune e condiviso riesce a dare.
Ieri mattina il server che ospita l'istanza Bookwyrm di Livello Segreto non si è sentito molto bene: il disco principale ha terminato lo spazio libero e i container che fanno girare i servizi si sono fermati improvvisamente (non li biasimo, avrei fatto lo stesso).
Tralasciando le azioni migliorative da apportare al server stesso (e l’allestimento di un sistema di monitoraggio che mi devo studiare per bene) mi sono ritrovato – anche a valle della pulizia del disco e l’aumento dello spazio disponibile – una buona parte dello stack di Bookwrym ancora in protesta (sito up and running, ma con un errore generico al posto del contenuto).
Dando un’occhiata ai log ho notato che entrambi i container di Redis non hanno apprezzato molto quanto avvenuto e non erano in grado di ripartire. L’errore a console era qualcosa di questo tipo:
Bad file format reading the append only file appendonly.aof.45.incr.aof: make a backup of your AOF file, then use ./redis-check-aof --fix <filename.manifest>
Redis è gentilissimo e fornisce anche la soluzione al problema, ma come trovo la posizione di quel file? E come posso lanciare il comando indicato per sistemare la situazione?

 fonte:
fonte: